GPT-5
(I wrote this quickly for my own edification. It isn't original thinking; it condenses takes I’ve read on X over the past few days. Where relevant I’ve linked tweets. I hope it’s helpful for people outside the bubble.)
Watching an OpenAI launch now feels like watching an Apple keynote in the early 2010s. As a kid, I was giddy about which new, unaffordable iPhone would drop. I’ll probably look back on my twenties as the years I felt the same mix of excitement and perhaps fear about whatever OpenAI released next.
At first glance on X, before I had access to the model, the mood was mostly disappointment. Some people pushed their timelines out; a few even talked about the end of the pre-training paradigm. The live presentation had a couple of funny slip-ups.
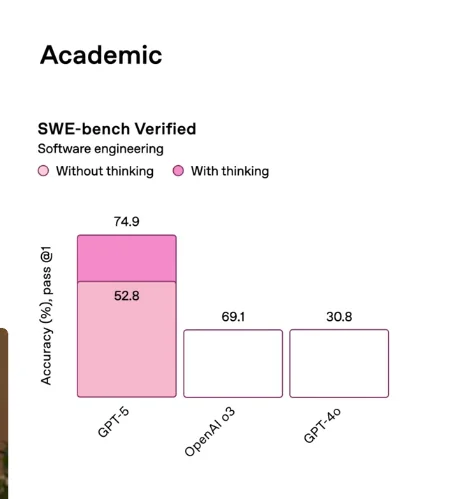
I’m not a technical person, and my naive expectation was that GPT-5 would feel as big a jump as GPT-3 to GPT-4. I now think two things are true at the same time:
a) GPT-5 is not a big step up from GPT-4.
b) That doesn’t mean AI progress has stalled.
a) does not entail b).
GPT-5 isn’t a brand-new base model or a push to a new state of the art. It’s more of a product release: a family of models plus a router. You get a general GPT-5 for most tasks, a “thinking” variant for harder ones, and the system picks which to use for your prompt.
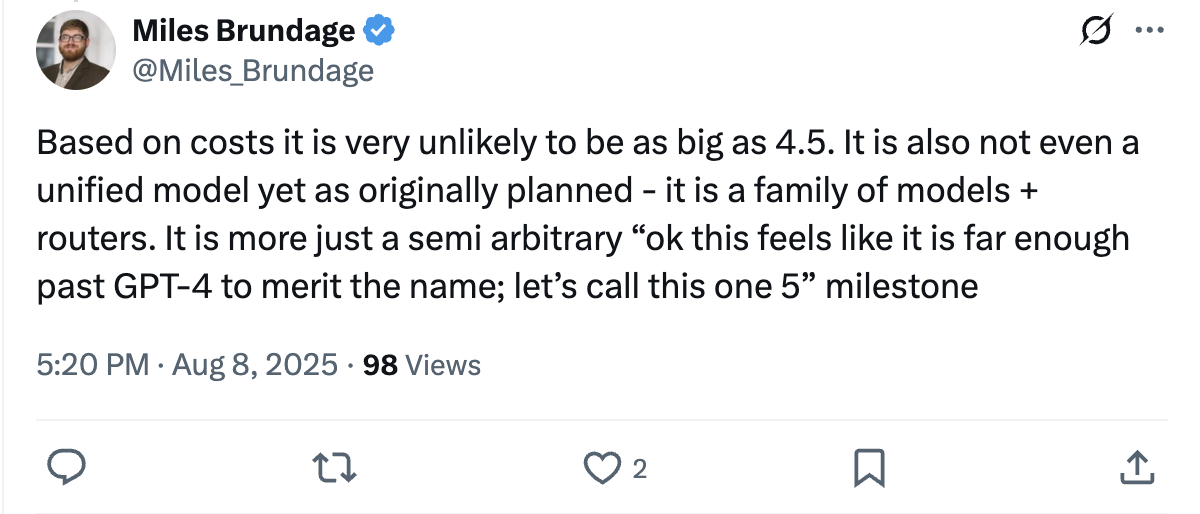
On compute, the big jumps have come from scale up in pre-training compute. GPT-3 → GPT-4 was roughly a hundred-fold; GPT-4 → 4.5 about an order of magnitude. Epoch think GPT-5 isn’t a major scale-up over 4.5, which also fits the lower cost and faster outputs. That doesn’t mean pre-training is over; it more likely means the next big scale up in pre-training will happen further down the line.


Where the push may go next is RL. RL sits after pre-training and shapes behaviour. If we want broader, task-agnostic capability, we probably need far better, and far bigger, RL environments and rewards. Mechanize call this “replication training”: thousands of diverse, auto-graded tasks that let you scale RL the way we once scaled pre-training.

Okay, so if a) is true, what about b)?
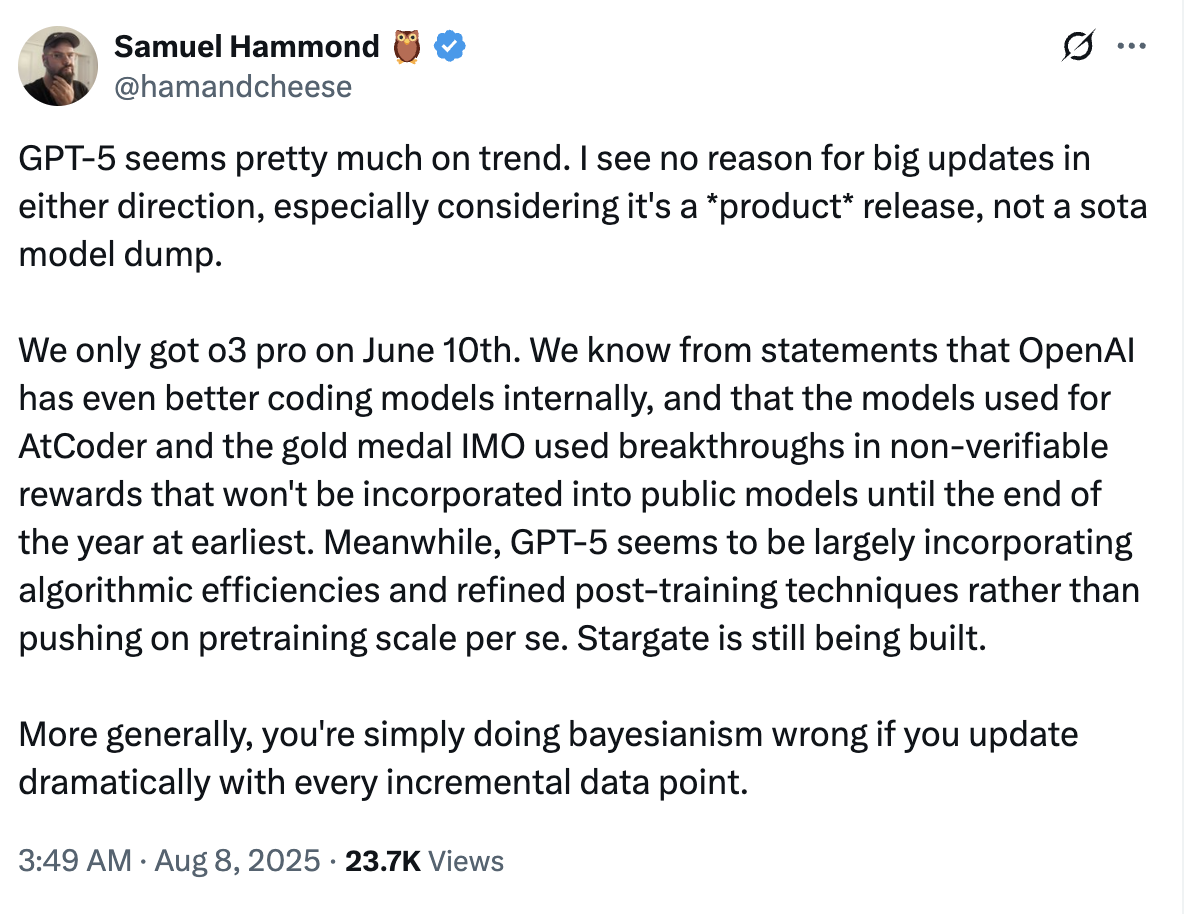
I think the tweet below does a good job of summarising this, but to me, the ‘progress has stalled’ feeling is mostly expectation inflation, ours and OpenAI’s. Calling it “GPT-5” and hyping the launch, perhaps to keep pace with competitors, seems to have backfired. Still, things look on trend for long-horizon tasks, and we are certainly not out of the weeds on making sure the next big jump goes well.
Feedback welcome. If something here is off, I’ll correct it - gauraventh at google's main mailing service